สร้าง Traindata สำหรับ OCR ด้วย Tesseract
Tesseract OCR
Tesseract OCR เป็น Engine ที่ใช้สำหรับการรู้จำอักขระทางภาพ พัฒนาขึ้นโดยบริษัท HP ระหว่างปี 1984-1985 โดยเริ่มต้นมาจากโปรเจควิจัยระดับปริญญาเอกในห้องปฏิบัติการณ์ HP โดยมีความตั้งใจเพื่อนำไปใช้กับงานเครื่องสแกนเนอร์เป็นหลัก ซึ่งในปี 2005 HP ก็ได้ปล่อยให้เป็น Open Source โดยมี google เป็นผู้สนับสนุน ซึ่งนักพัฒนาสามารถนำชุดคำสั่งนี้มาใช้งานได้ Tesseract นั้นถือว่าเป็นหนึ่งใน OCR Open Source ที่มีความแม่นยำสูง สามารถเข้าไปดาวน์โหลดได้ที่ https://code.google.com/p/tesseract-ocr/
Training Step
Step : 1
สร้างไฟล์ box ซึ่งเป็นไฟล์ที่ใช้ระบุตำแหน่งของอักขระต่างๆ ที่อยู่ในรูปภาพที่จะนำมาใช้ฝึกฝน โดยตำแหน่งของอักขระจะถูกระบุเป็นพิกัด ซึ่งมีโปรแกรมที่แจกฟรีสำหรับการนำมาใช้สร้างไฟล์ box เช่น txt2img, jTessBoxEditor, Qt-box-editor ฯลฯ
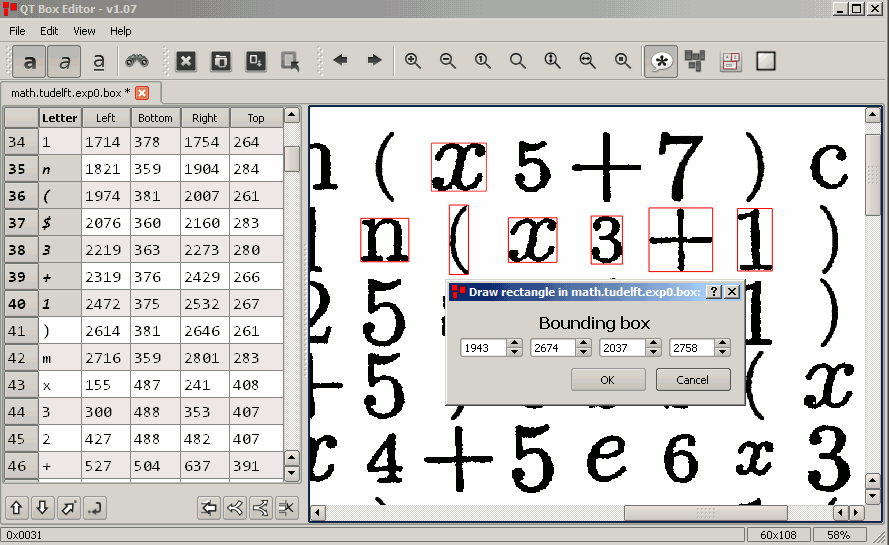 |
| หน้าตาโปรแกรมของ Qt-Box Editor (Source : http://zdenop.github.io/qt-box-editor/) |
Step : 2
เมื่อมีไฟล์ box และรูปภาพที่ต้องการแล้ว ก็นำไฟล์ทั้งสองเข้าสู่ Tesseract-OCR โดยเรียกการใช้งานผ่าน command prompt โดยใช้คำสั่ง
tesseract tha.test_font.exp0.png tha.test_font.exp0.box nobatch box.train
Step : 3
ใช้ utility unicharset_extractor เพื่อสร้างไฟล์ unicharset โดยใช้คำสั่ง
unicharset_extractor tha.test_font.exp0.box
Step : 4
สร้างไฟล์ font_properties ให้อยู่ใน directory เดียวกัน (เจ้าของบล๊อคใช้โปรแกรม Notepad++) โดยเซฟชื่อว่า tha.font_properties โดยข้อความภายในให้มีรูปแบบดังนี้
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
โดย fontname คือ ชื่อของ font ที่เราต้องการจะ train ซึ่งในที่นี้คือ test_font ส่วน
test_font 0 0 0 0 0
Step : 5
ใช้คำสั่ง shapeclustering
shapeclustering -F font_properties -U unicharset tha.test_font.exp0.tr
Step : 6
ใช้คำสั่ง mftraining
mftraining -F font_properties -U unicharset -O tha.unicharset tha.test_font.exp0.tr
Step : 7
ใช้คำสั่ง cntraining
cntraining tha.test_font.exp0.tr
Step : 8
ใช้คำสั่ง combine_tessdata เป็นการสิ้นสุดของกระบวนการ
combine_tessdata tha.
เมื่อเสร็จเรียบร้อยแล้ว จะได้ไฟล์ tha.traineddata มา ซึ่งสามารถนำไปใช้เป็นไฟล์ข้อมูลสำหรับทำกระบวนการ OCR ได้


Comments
Post a Comment